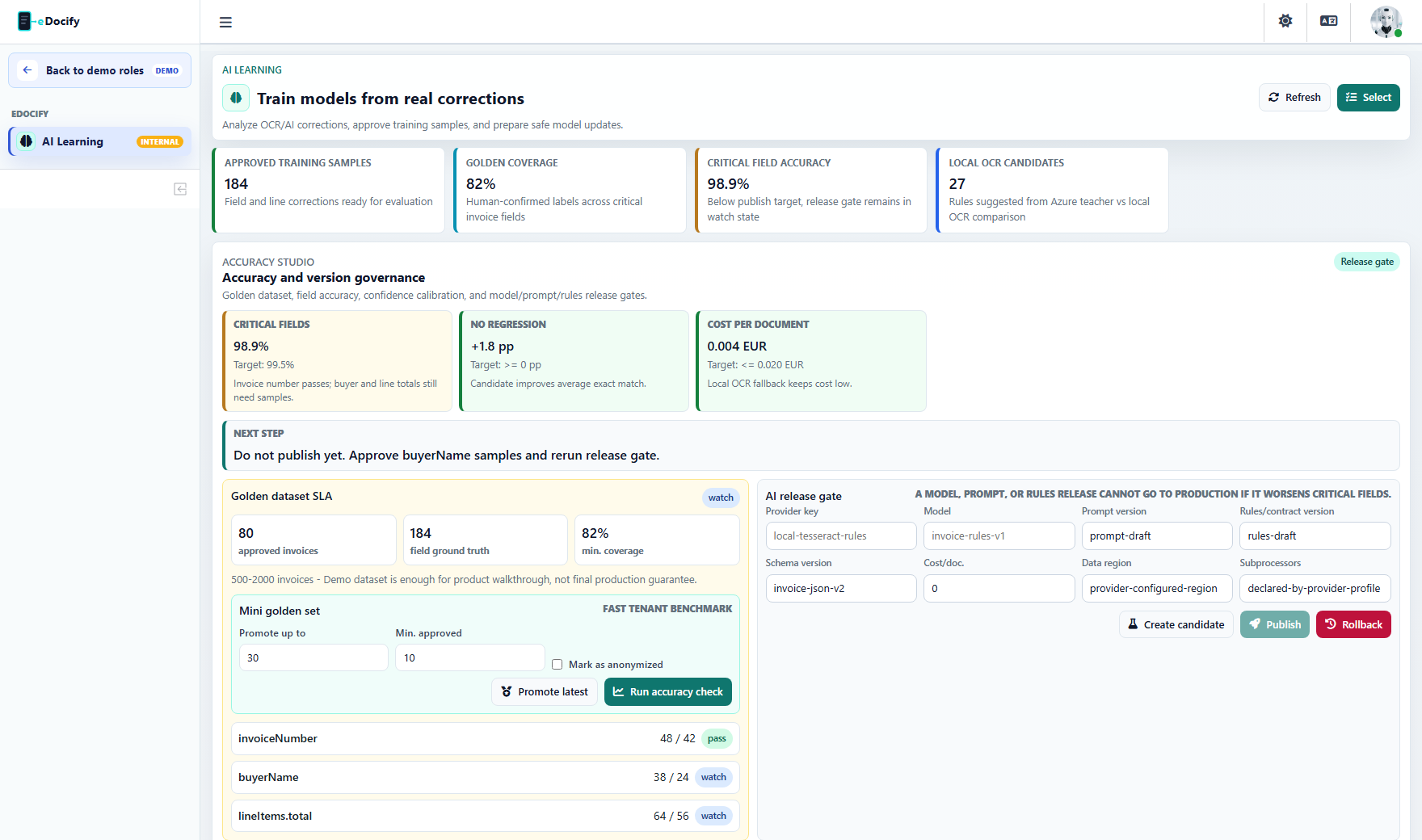
Accuracy Studio and AI Learning
Accuracy Studio and AI Learning help eDocify improve recognition quality without losing control.
The problem
OCR accuracy cannot be trusted only because a provider returns a high confidence value. Confidence must be compared with real corrected data and golden datasets.
Golden dataset
A golden dataset is a set of documents with human-approved truth:
- original file;
- OCR raw text;
- expected header fields;
- expected line items;
- expected validation outcomes;
- supplier and document type metadata;
- anonymized data where needed.
Recommended pilot target:
- 100-200 documents for a serious customer pilot;
- 500-2,000 documents for stable provider benchmark;
- coverage across suppliers, layouts, scans, languages, and line complexity.
Provider bake-off
Provider bake-off means running the same dataset through several routes:
- Azure Document Intelligence;
- Mistral OCR;
- OpenAI structured extraction;
- Tesseract + rules;
- PaddleOCR + rules;
- hybrid route.
Compare:
- field accuracy;
- line item accuracy;
- missing fields;
- false positives;
- latency;
- cost;
- error rate;
- review time.
Quality Engine
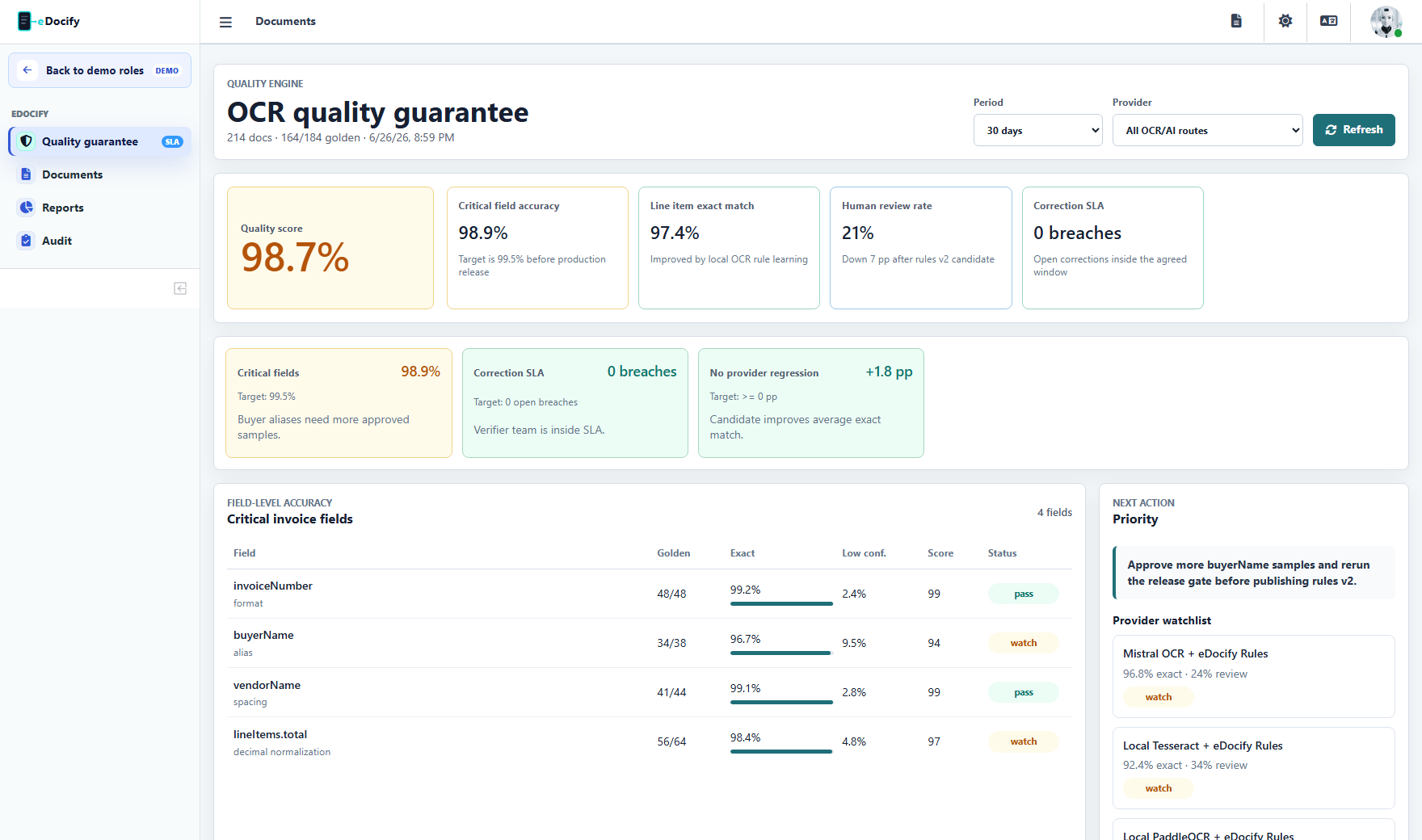
Quality Engine should show:
- critical field target, for example 99.5 percent after review;
- watch target, for example 97 percent before escalation;
- correction SLA;
- provider benchmark;
- QA sampling;
- line quality;
- customer-specific guarantee state.
Release gate
New model, prompt, provider, or rule version should pass a release gate:
- Select dataset and customer scope.
- Run current production version.
- Run candidate version.
- Compare field and line accuracy.
- Mark improved, neutral, or regressed fields.
- Require approval for publish.
- Keep rollback available.
Human correction loop
Corrections are training signals:
- original value;
- corrected value;
- field key;
- document type;
- supplier;
- OCR text;
- provider;
- reason;
- user and timestamp.
These signals can feed:
- rule suggestions;
- supplier memory;
- field candidate ranking;
- provider routing;
- model evaluation.
Azure teacher mode
Azure Document Intelligence can be used as a teacher during early training:
- run premium extraction;
- store structured result;
- run local OCR on same document;
- compare local OCR + rules to Azure structure;
- learn supplier patterns;
- improve local rule extraction;
- benchmark cost reduction.
Human-approved golden data remains stronger than provider-to-provider comparison.